Ollama - Running Large Language Models on Your Machine
Table of Contents
With the increasing popularity and capabilities of language models, having the ability to run them locally provides a significant advantage to develop and research these models locally. Ollama is an open-source command line tool that lets you run, create, and share large language models on your computer.
Ollama allows you to run large language models, such as Llama 2 and Code Llama, without any registration or waiting list. Not only does it support existing models, but it also offers the flexibility to customize and create your own models. You can find the list of supported models in Ollama Library.
You can easily import the models from the Ollama library and start working with these models without installing any dependencies.
What is Large language models (LLMs)? The Large language models are a type of artificial intelligence model based on deep learning architectures, specifically, transformer architectures like GPT (Generative Pretrained Transformer) and BERT (Bidirectional Encoder Representations from Transformers). They are trained on vast amounts of text data and can understand and generate human-like text based on the input they receive.
Getting Started
To begin your journey with Ollama, simply head over to their download page and get the appropriate version for your operating system.
Running Ollama As A Command-line (CLI)
After installing Ollama, you can run a desired model by using the following command in your terminal:
ollama run llama2
If the model is not available locally, this command will initiate the download process first. Once the model is downloaded, it will prompt for a chat with the model:
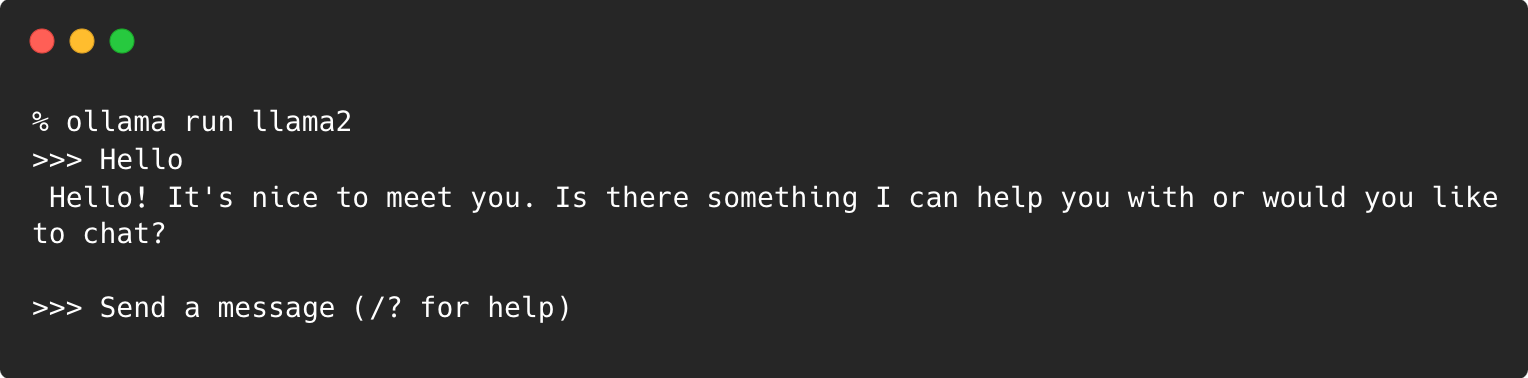
That’s it! You can start asking questions to the locally running model.
Running Ollama As A Server
Ollama can also run as a server. It has an API for running and managing models. You can start the Ollama as server using following command:
% ollama serve
This command will start the Ollama server on port 11434:

Next, you can call the REST API using any client. In this example, let’s use the curl to generate text from the llama2 model to find out who is the best batsman in the game of cricket:
curl -X POST http://localhost:11434/api/generate\
-d '{ "model": "llama2", "prompt":"Who is the best batsman in the game of cricket?" }'
Ollama will serve a streaming response generated by the Llama2 model as follows:
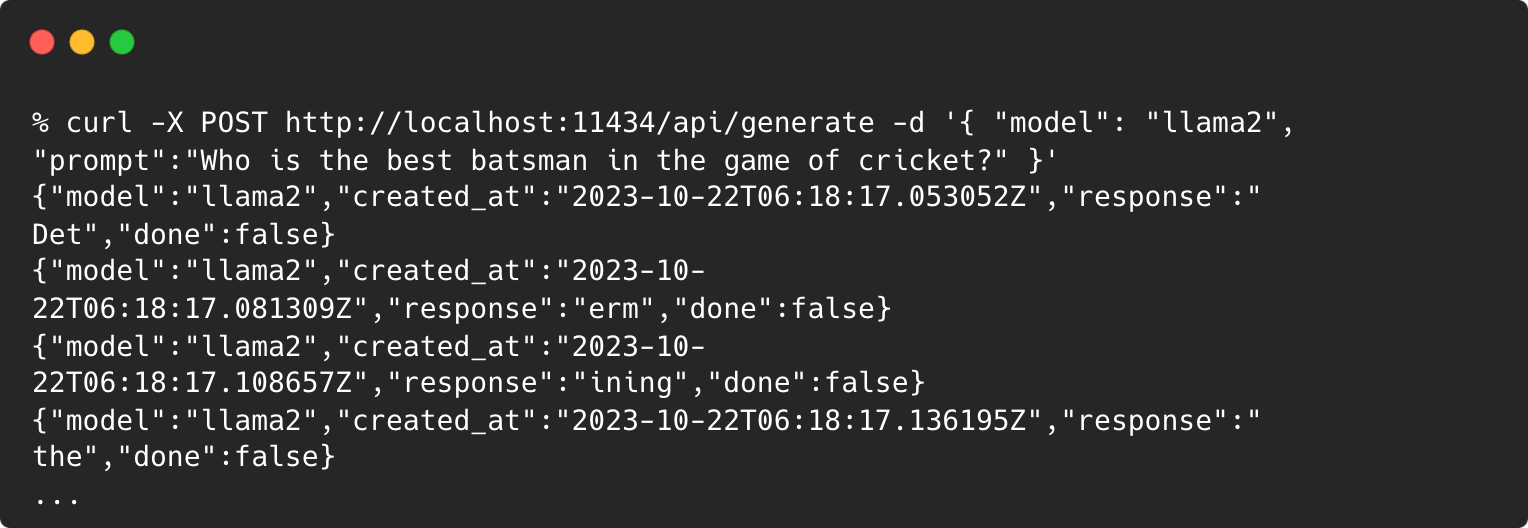
We will explore this further to build a local Chatbot using Ollama REST API and LangChain.
How It Works?
If you’re familiar with Docker, Ollama works in a similar way to Docker, providing an environment where anyone can pull, test, and tinker with machine learning models similar to handling Docker images.
-
Pulling Models - Much like Docker’s pull command, Ollama provides a command to fetch models from a registry, streamlining the process of obtaining the desired models for local development and testing.
-
Listing Available Models - Ollama incorporates a command for listing all available models in the registry, providing a clear overview of their options. This is comparable to Docker’s image listing functionality.
-
Running Models - With a simple command, anyone can execute a model, making it effortless to test and evaluate the model’s performance in a controlled or live environment.
-
Customization and Adaptation - Ollama goes a step further by allowing anyone to modify and build upon the pulled models, resembling the way Docker enables the creation and customization of images. This feature encourages innovation and the tailoring of models with prompt engineering. You can also push a model to a registry.
-
Ease of Use - By mimicking Docker’s command-line operations, Ollama lowers the entry barrier, making it intuitive to start working with machine learning models.
-
Repository Management - Like Docker’s repository management, Ollama ensures that models are organized and accessible, fostering a collaborative environment for sharing and improving machine learning models.
The Ollama Runtime
Ollama offers a runtime that manages the models locally. It provides a CLI & REST API, serving as an interface for users or systems to interact with the runtime and, by extension, the large language models. The runtime enables GPU Acceleration, which would significantly speed up the computation and execution of the model. The model results, which are the output or insights derived from running the models, are consumed by end-users or other systems.
Ending
Ollama offers a more accessible and user-friendly approach to experimenting with large language models. Whether you’re a seasoned developer or just starting out, Ollama provides the tools and platform to dive deep into the world of large language models.
In the next post, we will see how to customize a model using Ollama.
/bye