Test Run - Using Multimodal Vision AI in Test Automation
Table of Contents
Introduction
Multimodal models and computer vision represent a significant leap in the field of artificial intelligence, marking a transition from traditional AI systems that rely on single data types to more complex and holistic approaches. Multimodal models are designed to simultaneously process and interpret data from multiple sources – such as text, images, audio, and video. This ability to integrate diverse data types allows these models to mimic human-like understanding more closely, making them incredibly powerful in interpreting real-world scenarios and nuances.
The applications of multimodal models and computer vision are vast and varied. For example, in healthcare, these technologies can analyze medical images and patient histories to assist in diagnosis and treatment plans. In the automotive industry, they power advanced driver-assistance systems (ADAS) and autonomous vehicles, where the integration of visual, auditory, and sensory data is crucial for safe navigation. In retail and e-commerce, multimodal models enhance customer experience through personalized recommendations by understanding customer preferences through visual and textual cues.
These applications only scratch the surface of what’s possible with multimodal models and computer vision. As these technologies continue to evolve, they are set to redefine the boundaries of AI’s capabilities, offering more intuitive, efficient solutions aligned with human ways of processing information.
Using Multimodal Models In Test Automation
In this post, I’ll delve into the use of multimodal model applications with test automation, with a particular focus on UI/UX testing. This exploration into multimodal models represents a cutting-edge approach, pushing the boundaries of conventional test automation techniques. As these models continue to develop and mature, we anticipate a parallel evolution in their applications and the outcomes they can achieve. This field is dynamic and rapidly advancing, suggesting that the potential applications of multimodal models in test automation are only beginning to be realized.
Recently, I came across an exciting update from Ollama on Twitter announcing the availability of new LLaVA multimodal model, capable of processing images.
This announcement resonated with my long-standing interest in applying computer vision to testing applications. Motivated by this development, I decided to conduct a practical experiment with the model. My plan is to leverage Ollama’s platform to download and execute the LLaVA multimodal model locally, giving me firsthand experience of its capabilities in a test environment. This step represents a significant move towards integrating advanced computer vision techniques into practical testing scenarios.
Large Language and Vision Assistant - LLaVA is a multimodal model that combines a vision encoder and Vicuna for general-purpose visual and language understanding, achieving impressive chat capabilities mimicking the spirits of the multimodal GPT-4.
Use Case - UI/UX Testing Agent
Imagine we’re engaged in testing a web application using automation tools like Selenium, Cypress, or Playwright. All these tools possess the capability to capture screenshots during testing. Now, think about enhancing this process by integrating computer vision for UI/UX testing on these screenshots. The idea here is to employ a model that can provide feedback akin to a human UI/UX expert, based on specific instructions or prompts. For instance, in this scenario, I would instruct the model to analyze a screenshot as if it were a UI/UX expert, and then provide its insights or recommendations about the screen’s design and usability. This approach could significantly augment traditional automated testing by adding a visual and design analysis layer that closely mirrors human evaluation.
The following sequence diagram illustrates the concept of a UI/UX testing agent:
-
Test Automation Script - The Test Automation Script using the desired tool initiates the testing process by interacting with the Web Application. This involves executing predefined test cases on the web application to assess its functionality, performance, and overall user experience.
-
Web Application - In response to the actions of the Test Automation Script, the Web Application renders its User Interface (UI). This involves displaying the various elements of the web application as a user would typically see them during interaction.
-
Capture Screenshot - The Test Automation Script then captures a screenshot of the Web Application’s UI. This step is crucial as it freezes the current state of the UI for further analysis. The capturing of the screenshot indicates a key point in the testing process where the script collects visual data.
-
Send Screenshot to Model - Once the screenshot is captured, the Test Automation Script sends it to the Model running in Ollama for analysis. The Model represents an advanced AI system capable of processing and analyzing visual data, presumably using computer vision and image analysis techniques.
-
Analyze Screenshot - Inside the Ollama Model, the screenshot undergoes analysis. This step is where the model applies its algorithms to evaluate various aspects of the UI, such as layout, color schemes, element alignments, and overall aesthetics, to provide insights similar to what a human UI/UX expert would offer.
-
Analysis Response - After completing the analysis, the Model sends its findings back to the Test Automation Script. This response likely includes detailed feedback or a report on the UI/UX aspects of the web application, as analyzed from the screenshot.
-
Report to User - Finally, the Test Automation Script relays the analysis response to the User. This step involves presenting the findings of the Model’s analysis to the user, typically in the form of a report. In this context, the user could be a test engineer, a UI/UX designer, or any other stakeholder interested in the UI/UX test results.
Running The Multimodal Model With Ollama
Ollama is an open-source tool that lets you run, create, and share large language models on your computer. I’ll use Ollama to run the LLaVA model.
Let’s run the LLaVA model using Ollama command line:
ollama run llava
After setting up the model, let’s input a test image to evaluate the model’s response and assess its capabilities using the command line.
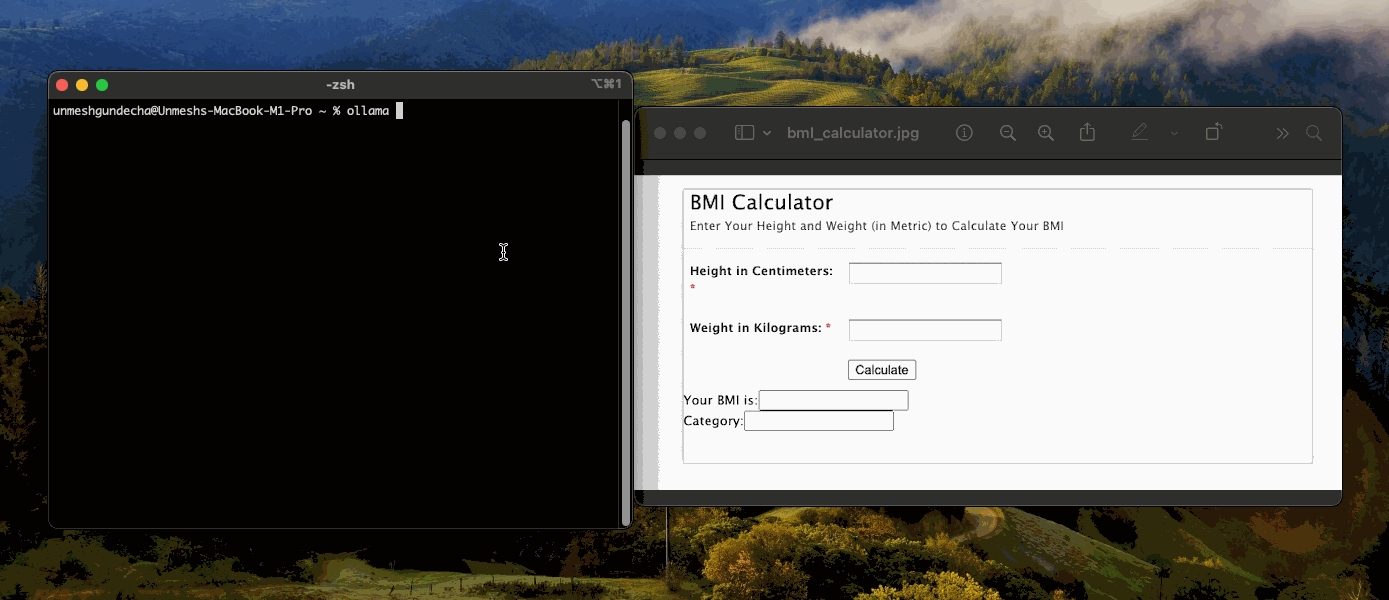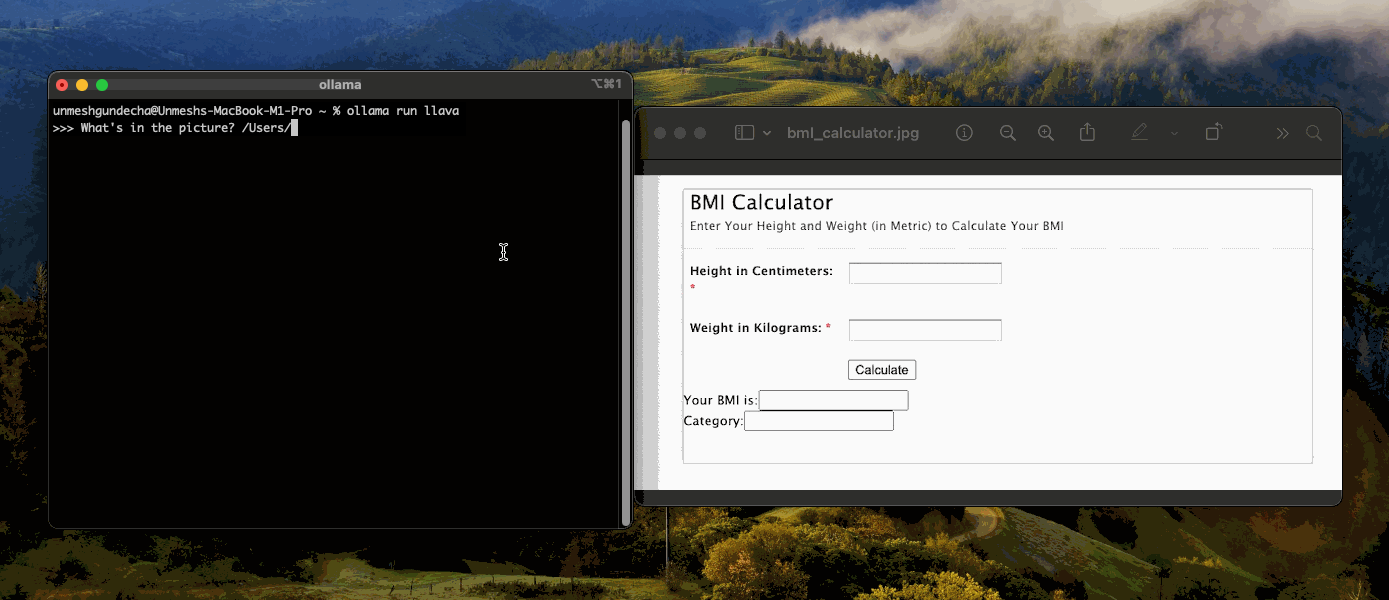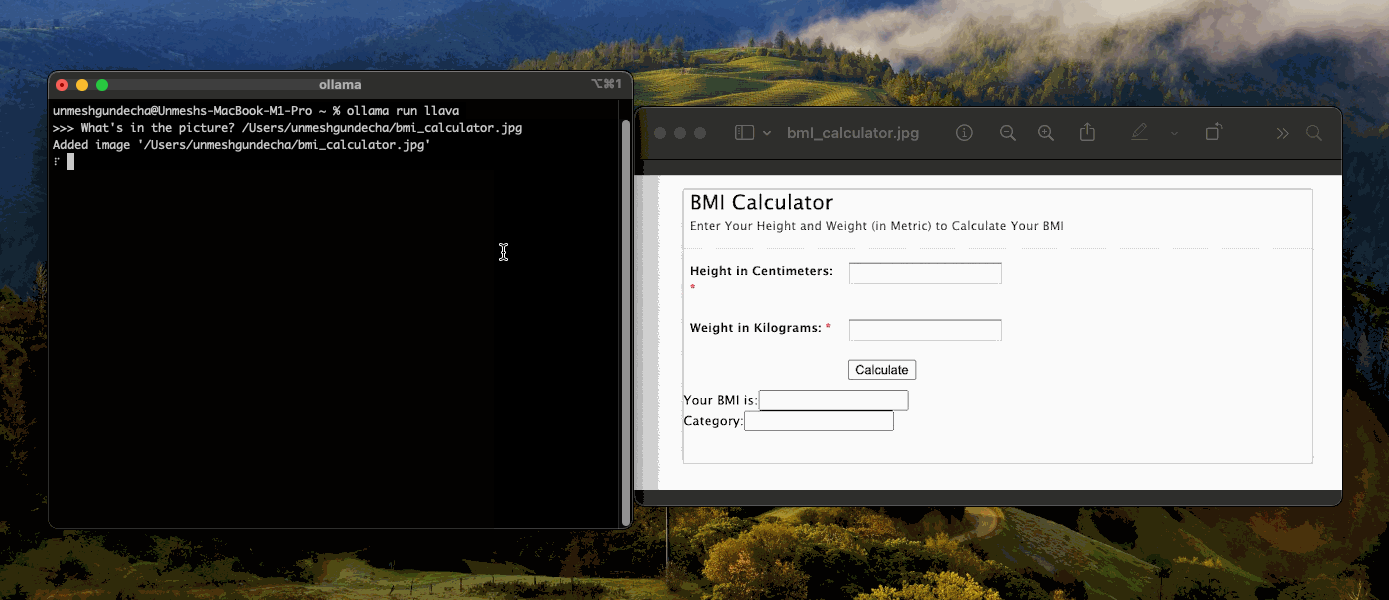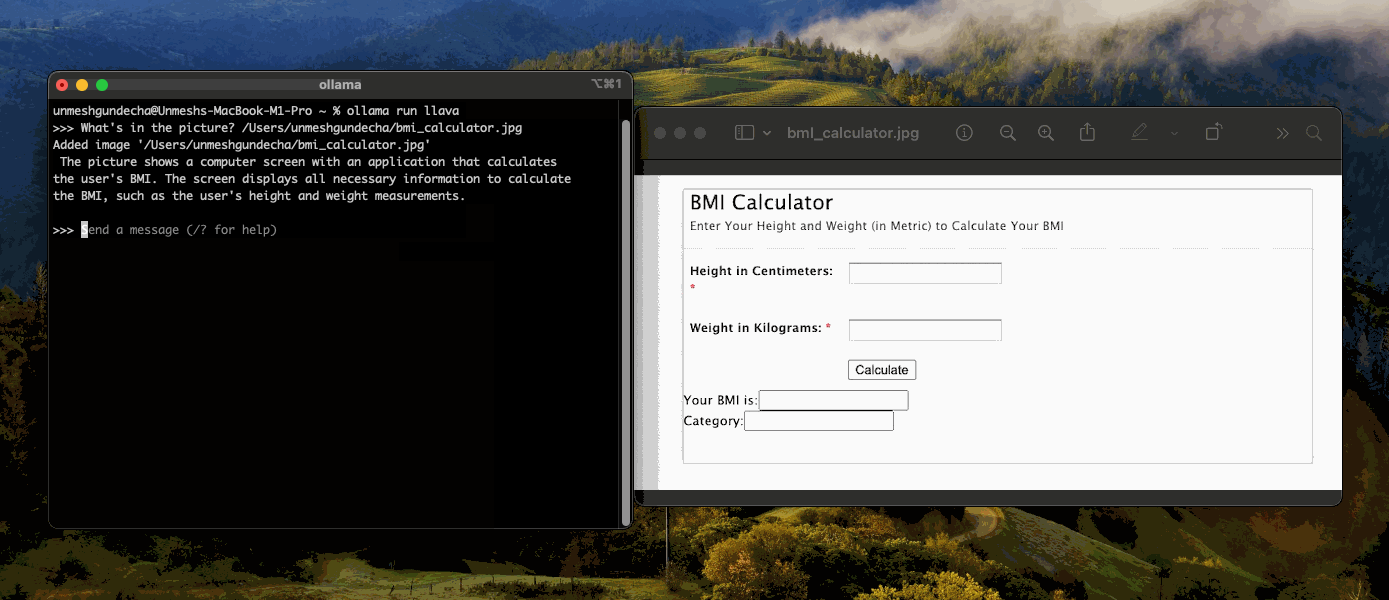
The model identified the image as a BMI calculator page and correctly interpreted its function.
Using the LLaVA Model In Test Automation
In this part, I will demonstrate using a Selenium script to conduct a test on a sample application, leveraging the capabilities of the LLaVA model for enhanced analysis.
The Test Automation Script
I’ve set up a Python script with Selenium to visit a BMI Calculator webpage to capture its screenshot. The script is designed to open a Chrome browser, navigate to the specified application, and then take a screenshot, which it saves as a base64 encoded string.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
import base64
# Page URL
your_page_url = 'https://cookbook.seleniumacademy.com/bmicalculator.html'
# Setup Chrome options
chrome_options = Options()
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
# Set path to chromedriver as per your configuration
webdriver_service = Service(ChromeDriverManager().install())
# Choose Chrome Browser
# Choose Chrome Browser
driver = webdriver.Chrome(service=webdriver_service,
options=chrome_options)
try:
# Get page
driver.get(page_url)
# Get screenshot as base64
base64_encoded_string = driver.get_screenshot_as_base64()
finally:
# Close browser
driver.quit()
Calling Ollama API In Test Automation Script
Ollama is a versatile tool designed for interacting with large language models (LLMs). It stands out for its ability to simplify complex AI interactions, making LLMs more accessible to a wider range of use cases. The Ollama API is central to this functionality, acting as a bridge between applications and the models. The Ollama API, with its well-defined set of commands and responses, enables users to effectively harness the capabilities of LLMs, facilitating a range of tasks from data analysis to natural language processing.
I’ll use the POST /api/generate API in the Selenium script. This API accepts the following parameters:
model- The name of the model required. E.gllava.prompt- The prompt to generate a response for.images- The list of images as base64 strings.stream- Iffalse, the response will be returned as a single response object, rather than a stream of objects.
To guide the model to function as a UI/UX expert and deliver feedback on the provided screenshot, we must communicate this specific role through the prompt parameter. This instructs the model on the context and perspective from which to analyze the screenshot, ensuring that the feedback aligns with UI/UX expertise.
Let’s adjust the script to incorporate the Python requests module, enabling it to interact with the POST /api/generate endpoint of the Ollama server, which I have set up locally.
import requests
import json
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
page_url = 'https://cookbook.seleniumacademy.com/bmicalculator.html'
# Setup Chrome options
chrome_options = Options()
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
# Set path to chromedriver as per your configuration
webdriver_service = Service(ChromeDriverManager().install())
# Choose Chrome Browser
driver = webdriver.Chrome(service=webdriver_service,
options=chrome_options)
prompt = """
As a UI/UX expert, you are presented with a screenshot of a BMI Calculator page.
Your task is to meticulously evaluate and provide detailed feedback.
Focus on aspects such as the overall user interface and
user experience design, alignment, layout precision, color schemes, and textual content.
Include constructive suggestions and potential enhancements in your critique.
Additionally, identify and report any discernible errors, defects,
or areas for improvement observed in the screenshot.
"""
try:
# Get page
driver.get(page_url)
# Get screenshot as base64
base64_encoded_string = driver.get_screenshot_as_base64()
# Define the API endpoint
api_endpoint = "http://localhost:11434/api/generate"
headers = { 'Content-Type': 'text/plain' }
# Define the data payload with prompt and image
data_payload = {
"model": "llava",
"prompt": prompt,
"stream": False,
"images": [base64_encoded_string]
}
# Send the POST request to the Ollama API endpoint
# running the llava model
response = requests.post(api_endpoint, headers=headers,
data=json.dumps(data_payload))
# Assuming the API returns a JSON response
response_data = response.json()
# Print response
print(response_data)
finally:
# Close browser
driver.quit()
This script uses the requests library to interact with the Ollama API and engage with the LLaVA model. Upon receiving the defined prompt or set of instructions, the LLaVA model will process the image and generate feedback accordingly. The output generated by the model is expected to be structured as follows, providing specific and insightful feedback based on the image analysis:
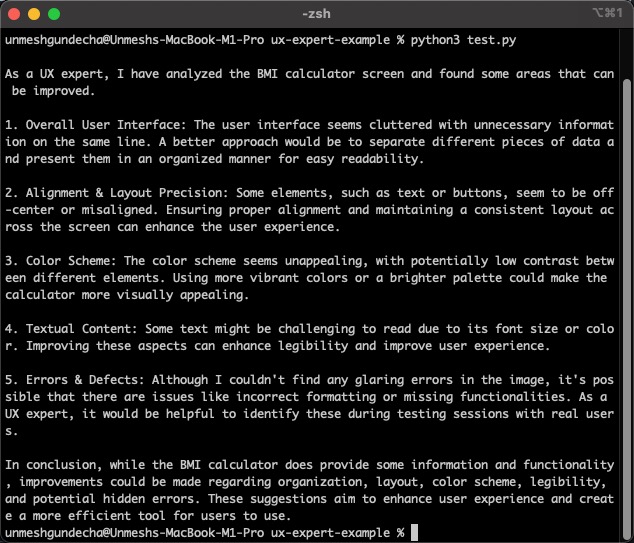
Generating Report
To conclude this example, I will enhance the script by adding functionality to create a PDF report using the reportlab module. This report will include both the screenshot of the page and the feedback provided by the model. This PDF can then be conveniently shared with stakeholders for review and further action.
Additionally, I will organize and refine the code to ensure it is modular and easily reusable, enhancing its utility for future testing scenarios.
import requests
import json
import io
import base64
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from reportlab.platypus import SimpleDocTemplate
from reportlab.platypus import Table, TableStyle
from reportlab.platypus import Image, Paragraph
from reportlab.lib.styles import getSampleStyleSheet
from reportlab.lib.pagesizes import letter
from reportlab.lib import colors
# A function to perform the analysis
# using the Ollama API
def perform_ui_ux_analysis(page_name, image):
prompt = f"""
As a UI/UX expert, you are presented with a screenshot of {page_name} page.
Your task is to meticulously evaluate and provide detailed feedback.
Focus on aspects such as the overall user interface and
user experience design, alignment, layout precision, color schemes, and textual content.
Include constructive suggestions and potential enhancements in your critique.
Additionally, identify and report any discernible errors, defects, additional features,
or areas for improvement observed in the screenshot.
"""
# Define the API endpoint
api_endpoint = "http://localhost:11434/api/generate"
headers = {'Content-Type': 'text/plain'}
# Define the data payload with prompt and image
data_payload = {
"model": "llava",
"prompt": prompt,
"stream": False,
"images": [base64_encoded_string]
}
# Send the POST request to the Ollama API endpoint
# running the llava model
response = requests.post(api_endpoint, headers=headers,
data=json.dumps(data_payload))
# Assuming the API returns a JSON response
response_data = response.json()
# Generate the report
generate_report(response_data, f"{page_name}_report.pdf", base64_encoded_string)
# A function to generate the PDF report
def generate_report(json_data, filename, base64_image):
doc = SimpleDocTemplate(filename, pagesize=letter)
story = []
# Decode the base64 image data
image_data = base64.b64decode(base64_image)
# Resize the image (width, height)
image = Image(io.BytesIO(image_data), width=400, height=200)
story.append(image)
# Get a sample stylesheet
styles = getSampleStyleSheet()
# Convert the single dictionary JSON data to a list of Paragraphs
table_data = []
for key, value in json_data.items():
key_para = Paragraph(str(key), styles['Normal'])
value_para = Paragraph(str(value), styles['Normal'])
table_data.append([key_para, value_para])
# Define column widths
col_widths = [200, 300] # Adjust as necessary
# Create the table
table = Table(table_data, colWidths=col_widths)
table.setStyle(TableStyle([
('BACKGROUND', (0, 0), (-1, 0), colors.grey),
('TEXTCOLOR', (0, 0), (-1, 0), colors.whitesmoke),
('ALIGN', (0, 0), (-1, -1), 'LEFT'),
('FONTNAME', (0, 0), (-1, 0), 'Helvetica-Bold'),
('BOTTOMPADDING', (0, 0), (-1, 0), 12),
('BACKGROUND', (0, 1), (-1, -1), colors.beige),
('GRID', (0, 0), (-1, -1), 1, colors.black)
]))
# Add the table to the story
story.append(table)
# Build the PDF
doc.build(story)
page_url = 'https://cookbook.seleniumacademy.com/bmicalculator.html'
# Setup Chrome options
chrome_options = Options()
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
# Set path to chromedriver as per your configuration
webdriver_service = Service(ChromeDriverManager().install())
# Choose Chrome Browser
driver = webdriver.Chrome(service=webdriver_service,
options=chrome_options)
try:
# Get page
driver.get(page_url)
# Get screenshot as base64
base64_encoded_string = driver.get_screenshot_as_base64()
perform_ui_ux_analysis("BMI Calculator", base64_encoded_string)
finally:
# Close browser
driver.quit()
Upon running this script, it will generate a PDF report resembling the one illustrated below. The report will include the captured screenshot along with the analysis provided by the model, offering a comprehensive overview of the test results.

Building and deploying a custom model for UI/UX testing agent
Another impressive capability offered by Ollama is the ability to create custom models based on existing ones. This feature is akin to how ChatGPT agents can be customized. Using Ollama’s Modelfile, I’ve developed a specialized model tailored for our UI/UX Testing Agent and have made it available on the Ollama Hub.
This custom model is accessible for anyone to download and integrate into their projects, providing a convenient resource for those looking to enhance their test automation processes with advanced AI-driven insights.
Modelfile
# Modelfile for the UX Doctor
# Run `ollama create theuxdoctor -f ./Modelfile` and then `ollama run theuxdoctor` and enter a topic
FROM llava
PARAMETER temperature 1
SYSTEM """
As a UI/UX expert, you are presented with a screenshot of a given page.
Your task is to meticulously evaluate and provide detailed feedback.
Focus on aspects such as the overall user interface and
user experience design, alignment, layout precision, color schemes, and textual content.
Include constructive suggestions and potential enhancements in your critique.
Additionally, identify and report any discernible errors, defects, additional features,
or areas for improvement observed in the screenshot.
"""
Ending
The utilization of AI in this context serves as a preliminary step in the testing process. It flags potential UI/UX issues, allowing developers to make early adjustments. This can significantly streamline the development cycle, as it helps identify visual and usability problems when they can be addressed more easily.
However, the nuanced understanding, experience, and judgment of a human UI/UX expert are still crucial. The final review and approval of the UI/UX design should ideally be conducted by a professional in the field. They can assess aspects that automated systems might overlook, such as the emotional response of users, the alignment with brand identity, and the overall user journey experience, which often require a human touch and understanding.
Thus, while the integration of multimodal models like LLaVA in test automation scripts enhances the testing process and provides valuable insights, it complements rather than replaces the role of human experts.
The projects, such as The Self-Operating Computer framework, are set to make significant strides in technology. This particular tool is designed to enhance multimodal models like GPT-4-vision, enabling them to execute human-like interactions with computers, including mouse clicks and keyboard strokes.
This advancement signals a move away from traditional test automation and RPA tools, paving the way for the development of artificial general intelligence agents capable of more sophisticated, autonomous actions. This shift points to a future where the capabilities of automation and AI could be greatly expanded, opening up new possibilities in various applications.
/bye